Fable pushes coding toward another phase change
FrontierCode explains what programmers have been living with for the last year.
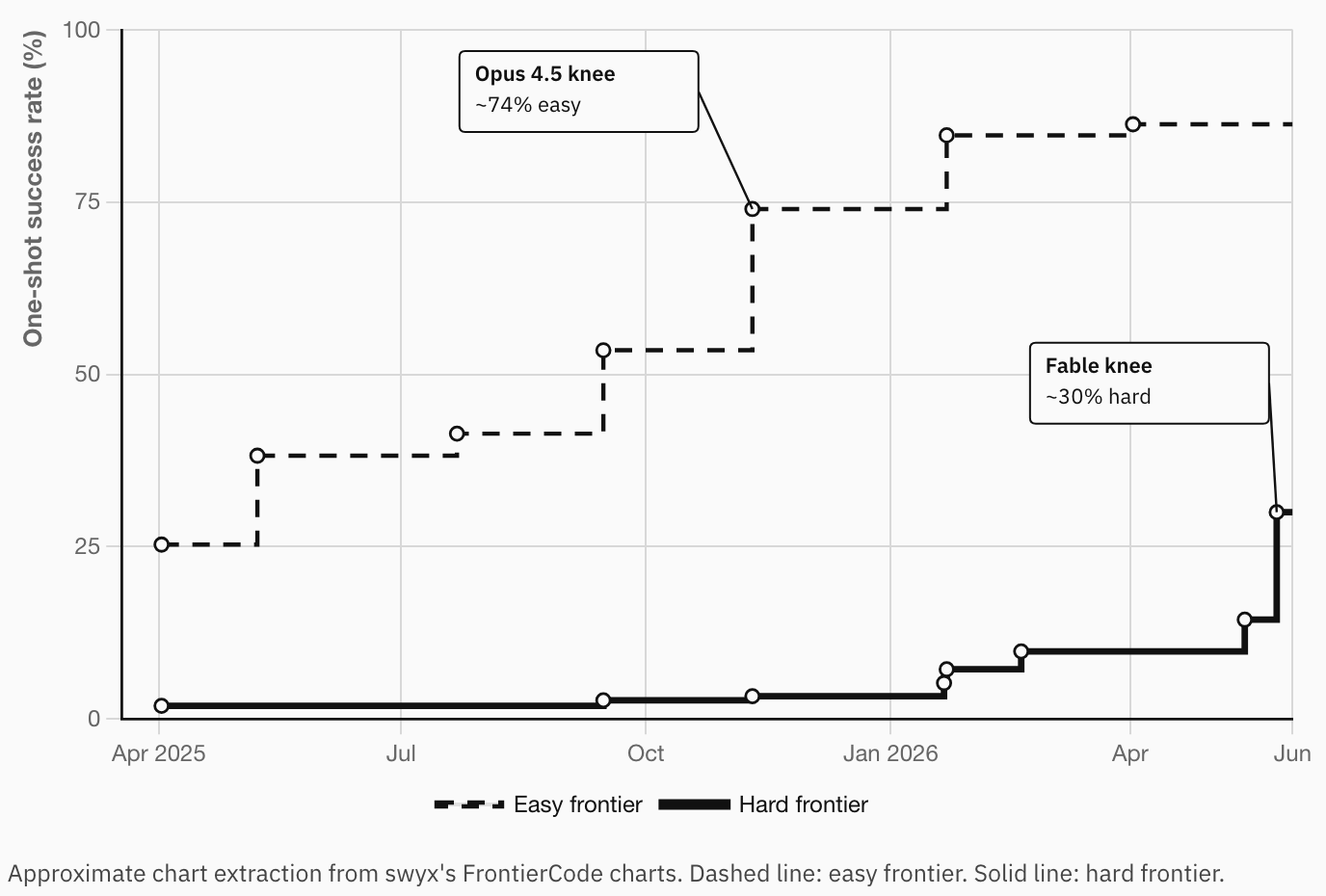
Shawn Wang at Cognition tweeted two charts from FrontierCode — the benchmark Cognition launched on Monday to test coding agents' ability to create fully mergeable pull requests. I pulled out the top-scoring models from those charts to highlight one of the stories he's telling.
What's going on in this chart?
FrontierCode has 150 problems split into three difficulty levels. Wang's tweets show one-shot performance on the easiest 50 and hardest 50 problems — meaning, the percentage chance that a model can fully solve a problem of that difficulty in a single attempt.
My summary chart shows the top model performance on those easy and hard problem sets over time — how good the best available model was at fully solving easy or hard problems in one try at every point over the last year or so. Call this the "easy frontier" and the "hard frontier."
These frontiers explain a lot about the experience of coding with agents over the last year:
- In November 2025, the easy frontier jumped from succeeding about half the time to about three quarters of the time. That was when many programmers noticed that vibe coding now worked. Before that jump, if you asked a model to edit a codebase repeatedly it would soon spiral into failure, spending more and more time to get less and less done. You had to go in and manually fix things up after each edit to keep things working. After that jump, you could keep making requests without reading the code in between, and on average it would improve.
- By February 2026, the easy frontier had saturated. New models brought no real advantage on easy tasks.
- Meanwhile the hard frontier had not saturated — but it was hard to feel the progress. Jumping between "solving hard problems 2% of the time" and "solving hard problems 4% of the time" is a huge accomplishment, but hard to detect in practice. Things were moving fast — GPT-5.3 doubled Opus 4.5, Opus 4.8 doubled GPT-5.3, Fable doubled Opus 4.8 — but felt like they were barely moving at all.
Fable gets into detectable numbers, though: according to FrontierCode it should now one-shot hard problems about one third of the time. That could be another November-2025-style phase change in what coding models can do.
Get new writing by email: